今回は、
タイトルの前回エントリの続きです。
主に
IISWの
2013年の
Forza Siliconの発表の内容から。
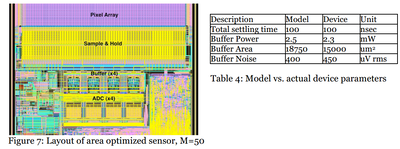
↑ 前回採り挙げたIISW2011年のForzaの発表資料から転載しわすれた、試作チップのレイアウト図
M=50(50列でADC等をshareした)の場合。
列で共有するバッファー部とADCとをチップ中央部に寄せてレイアウトし、左右の余ったスペースに”digital block”(恐らくセンサを駆動するタイミングジェネレータや信号処理用のDFEやDSPで、写真の右下のペルシャ絨毯模様みたいな方)と”reference generator circuitry”(列アンプや列ADC等に必要な基準電圧及び参照電圧生成回路で恐らく写真左下側に配置されている)が、チップが効率良く方形になるようにレイアウトされているようです。
右の表の方は、元々この発表自体は”ForzaがADC等を列で共有するこの種のセンサを作る時の諸条件(≒仕様)から最適値を設計時に求めることが出来るモデルを作りました”というのが主旨だったため、”実際試作したら、我々が立てたモデル通りの特性(バッファーの消費電力/レイアウト面積/ノイズ)のセンサが出来ました”というのをアピールするための結果になっていますね。
さて、
2013年の方はと言いますと、タイトルは
”Design of Analog Readout Circuitry with Front-end Multiplexing for Column Parallel Image Sensors”
2年経って、前回の2011の”Analysis”(分析)から”Design”(設計)にタイトルの冒頭がより実践的なものに変わっています。
 [2回]
[2回]
長くなるので、Abstruct(要約)とIntroduction(導入)部分に記載されている内容を簡単に箇条書きにすると、以下の様なものになっていると思います。
(例によってオレンジ色は私のコメントです)
■2011年以降も、アナログ読み出し回路を改善しながら我々の分析モデルを使い続けている
■我々の設計は、以下双方に対応可能な高いスケーラビリティーを持っている
・60fpsの高解像度 & ラージフォーマットセンサー
・600fpsの低解像度 & スモールフォームファクターセンサー
■その特徴は、高速の冗長性のある逐次比較型ADを含む全差動の読み出し回路にある
(ここで言う冗長性(redundant)というのは、逐次比較のADの際の容量ミスマッチに起因する比較エラーによるミスコードの発生を補償できたりすることを意味していると思われます)
■今回紹介するアナログ読み出し回路は、0.18um 3.3V/1.8VのCMOSプロセスによって製造されたプロトタイプセンサによってテストされた
■プロトタイプセンサを測定した結果、1列当たり126μWの消費電力、画素信号読み出しのスループットは17.5Mpixel/sec、でありながら、248μVの入力換算ノイズに抑えることが出来た
(来年2月にISSCCで発表する1.3億画素センサは60fpsなので、読み出し速度の面で17.5Mpix/secは物足りないものに感じるのですが、後で出てくる図面での1行の読み出し時間は1.9uSecと激速なので、何か私のこの部分の解釈が誤っている気がします)
■解像度とフレームレートを共に上げる要求が今もって強く、そのため画素の縮小を継続的に行う必要がある
■それを実現するためには、我々のアナログ読み出し回路の並列度を最適化するモデルが必要だ
■本発表では、前回(2011年)から改善した、高速逐次比較型ADCを含めた全差動のアナログ読み出し回路を紹介する
■今回の設計の結果、SN比を上げることに成功した一方で、供給電圧を低減出来、それゆえ全体的な消費電力を抑えることも出来た
基本以上でIntroduction終了で、以下図面を。
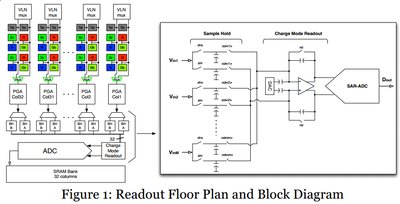
↑この大きさではわからないので、ご興味ある方はクリックして拡大して見てみてください。
まず、前回2011年に触れられておらず、そして今回も最後まで一切触れられていないのですが、この左図面では
垂直信号線も2列でマルチプレクスされて列アンプ(←図面中の”PGA”)へ入力されることになっています。
これも列アンプのレイアウト面積が(2列で一つ配置すれば良くなる為)小さく出来ることはわかるのですが、高速化に関係しているのか否か、これだけでは私にはわかりません。(←普通に考えれば高速化には寄与しないと考えるべきかと思います)
で、列アンプの出力後が、右図面の拡大図となるのですが、
更に図面中の右側の部分の”charge mode readout”の記載があるところから右側のADCまで含めて、
ここが”全差動”(fully differential)となったことが、abstructとintroductionを読む限り今回の発表で最も主張したい肝なポイント(≒前回から変化したところ)な様です。
もう少し補足しますと、
前回の図面では”S/H stage”の出力が一つで、それを受ける”buffer”の入力とそして出力も一つ(≒single end)で、その出力を受けるADCの入力も一つ という回路でした。
が、今回の回路は”sample hold”のCDS用のそれぞれ画素のリセット信号と光信号双方の信号がそのまま並列にbufferに別々に入力(←sample hold とbufferがそれぞれ2出力、2入力)されていて、その後のbufferの出力とSAR-ADCのそれぞれ出力と入力も、2出力、2入力となっています。
(SAR-ADCの中身の回路図は後ほど出てきます)
以下からが”Model Application”(モデルの適用?)の項。
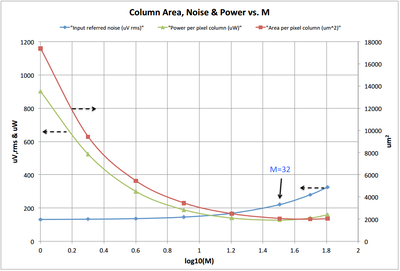
■センサのフレームレートを維持しながら、我々の制約(←面積、消費電力、ノイズなど)にミートする条件を吟味した結果、今回は32列で一つのADC等を共有する並列度とした
(上図の横軸1.5あたり。この図面の見方は前回と同様なので説明割愛します
注目点としては、前回と比べて、ノイズ(青線)が全般的に低く抑えられています。これが全差動型の回路にした利点なのでしょう。
そして恐らく全差動型の読み出し回路にしたせいで、レイアウト面積(赤線)は基本大きくなってしまったのだと思いますが、並列度=Mを大きくしていくと、徐々にその差はシングルエンド=前回と縮まり、M=32あたりではほとんど1列あたりのレイアウト面積に差がなくなっています。
ただ残念ながら、電源電圧は下げれたということですが、消費電力(緑線)は並列度Mのどこを取っても前回からは倍程度に増加してしまっているという結果になっています。私には何故消費電力が倍増してしまうのか、前回と今回の資料からは読み取れませんでした。
全般的に言って、前回と比較すると、”消費電力は増加してしまうが、ノイズ低減を優先した”という設計思想(?)の様です。)
以下からは”Charge Mode Readout Circuit”の項。
Figure1の写真の右の図を参照しながら読み進めてください。
■列選択と同時に、アンプの加算ノードを通して所望のレベルに出力電圧をシフトするために、読み出し中にDACがレベルシフトする
■その結果として、アンプの出力電圧は、commonモードレベルを中心にして、-1Vから+1Vまで差動的に振幅する
■全差動信号方式とすることによって、バッファーアンプには+1.8しか電源を供給していないものの、その出力振幅はpeak to peakで2Vを確保できるようになった
(上記全差動信号方式にすることにより、出力振幅が同じ電源電圧のシングルエンドの2倍確保できるイメージは、このTIの資料のp.5の下部の図5を見るとわかりやすいです。)
■このバッファーアンプの等価回路図を以下図3に示す
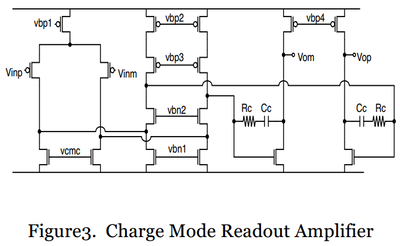
↑Vinp及びVinmがFigure1の中央部アンプのそれぞれ+と-が記載されている入力端。Vom、Vopが同じくその図面のアンプの対応する出力端。
■そのアンプ形態は、2stageのアンプで、1st stageがフォールデッドカスコード、2nd stageがcommon sourceとなっている
2nd stageの形態のお陰で、供給電圧を最大限生かした出力振幅を稼ぐことが出来る
(図の左から2ブロック分が上記で言うフォールデッドカスコードと呼んでいる部分。この資料のp.24から始まる説明がまさしく上の回路図のフォールデッドカスコードの説明になっていて、要は低電圧駆動でも利得は稼ぎたいという欲張り型の変則フォールデッドカスコード?となっているようです)
■Charge mode readout 及びAD変換中のタイミングを以下図4に示す
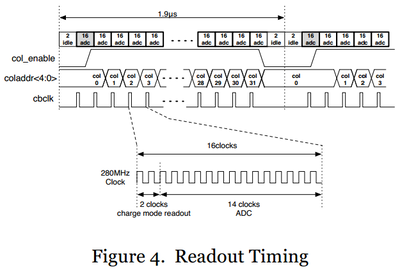
■1列(≒1画素)の信号を読む時間は、バッファーアンプが信号増幅してADCに入力するための時間と、SAR-ADCがAD変換する時間とに分けられる。
そしてその内訳は前者が2clockで後者が14clock(の計16clock)。
(この後、clk周波数が280MHzと記載されているので、1clock≒3.57nSec。
つまり、バッファーアンプが信号を増幅するための時間が約7nSecで、1画素の信号を恐らく12bit精度で変換するのに要する時間が約50nSecの計57.14nSec。
12bit精度であろうにも関わらず逐次比較のAD変換に14clkを要すのは、あとで出てきますが、このADがredundant(≒冗長)な比較エラーを帳消しにする方式のADのためだと思われます。
ちなみに大変不思議なことに、この発表資料の中に具体的にADの分解能は○bitという記載がありません。「12bit精度だろう」と書いたのは、最後に出てくるDNL、INL特性図の横軸が4095であるように見えるためです。)
■高速の280MHzのクロックをセンサアレイ全体に渡って分配する一方で、その他全てのタイミングコントロール信号はlocalで生成している
このlocalタイミング生成することによって、それぞれの読み出しブロックが独立で操作することが出来、またそれ故、高速クロックの伝播遅延が、多くのアレイの並列ブロック数の拡張を妨げる要素にはならない。
(個人的にはこの発表で最も興味を引かれたところ。結局私の最大の疑問は、「アナログ信号をどうやったらこんなに速く読み出せるの?」というところ。
この施策があったところで、バッファアンプが上記の7nSecという様な短い時間でまともに信号増幅できるのか?という疑問は拭えません。
が、大きなチップの端から端までバッファアンプ等を駆動するためのパルス配線を這わせた際に、そのパルスの根元側と終端側では遅延やパルス自体の消滅によって全く同じタイミングでは信号を処理することが出来なくなってしまうはずです。
今回の”local”という単位が32列のことを指すのかどうかわかりませんが、例えば狭画素ピッチセンサで32列程度であれば、上記駆動パルスの遅延はほとんど気にしなくて良いレベルになるのだろうなという風には納得出来ます)
今回はここまでで力尽きました(^^;)
2013年のForzaの発表資料はこの後、”Redundant SAR ADC"の項へと移りますが、そこと”Conclusion”は次回に。
年明けとなってしまうかもしれませんが・・・(^^;)
PR
